
【2026年最新】ATS統合型AIスクリーニングにおける「False Negative」抑制と適合度スコアリングの最適化
新卒採用や大規模な中途採用において、数万件にのぼるエントリーシート(ES)や履歴書を人間がすべて精査することは、もはや物理的な限界を迎えています。そこで、人的資本経営の観点から注目されているのが、ATS(採用管理システム)と統合されたAIスクリーニングです。しかし、単純なキーワードマッチングでは、本来合格させるべき優秀な潜在層を不合格にしてしまう「False Negative(偽陰性)」のリスクが常に付きまといます。本記事では、最新の自然言語処理(NLP)を用いた適合度スコアリングの最適化と、精度向上のための閾値(Threshold)設計について、技術的・戦略的視点から解説します。
目次 (クリックで開閉)
1. AIスクリーニングにおける「False Negative」の正体
AIスクリーニングにおける最大の懸念は、ポテンシャルの高い候補者をシステムが誤って排除してしまう「False Negative」です。これは多くの場合、AIが学習データに含まれる「過去の合格者のパターン」に過剰適合(オーバーフィッティング)し、多様な経歴や非定型的な強みを持つ候補者を過小評価することで発生します。
例えば、特定の大学名や資格、あるいは「リーダーシップ」といった頻出キーワードの有無だけでスコアリングを行うと、文脈の中で語られる深い思考力や、異業種での卓越した実績を見落とすことになります。2026年の採用市場では、労働人口の激減に伴い、一人の優秀な人材の取りこぼしが事業成長に致命的な影響を与えるため、この「偽陰性」をいかにゼロに近づけるかがHRテクノロジーの至上命題となっています。
2. 適合度スコアリングを支えるNLP技術とデータの構造化
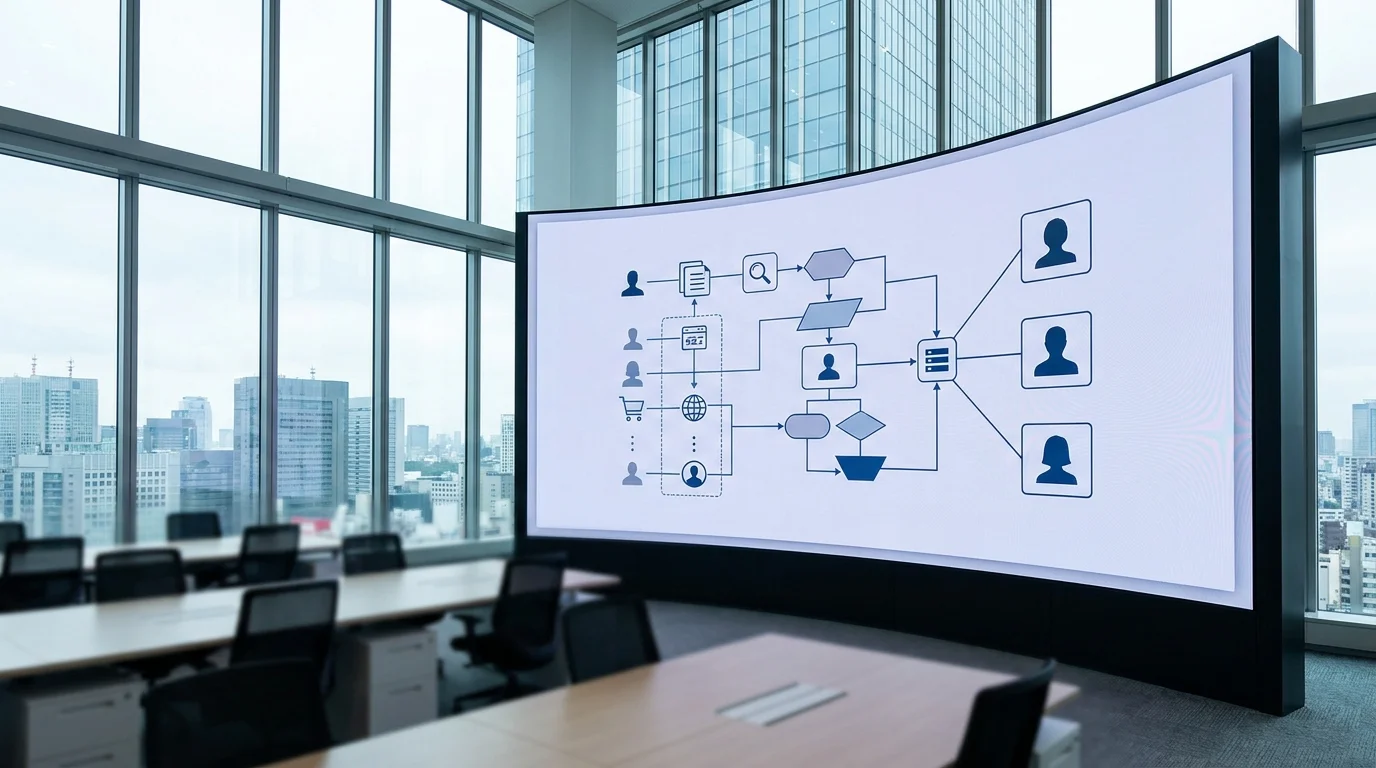
最新のAIスクリーニングでは、単なる単語の抽出ではなく、文章の文脈(コンテキスト)を理解する「大規模言語モデル(LLM)」を活用した自然言語処理(NLP)が導入されています。履歴書やESという非構造化データを、自社の評価軸(コンピテンシー・モデル)に沿った「構造化データ」へと変換するプロセスが重要です。
図1が示す通り、従来のキーワードマッチングからLLM統合型へと進化することで、偽陰性の発生率は劇的に低下します。これは、AIが候補者のエピソードから「論理的思考」「主体性」「共感能力」といった抽象的な概念を、セマンティック(意味論的)に抽出できるようになったためです。

3. 閾値(Threshold)設計による選考精度の最適化
AIが算出した「適合度スコア」をどのように選考に活かすか。ここで重要になるのが「閾値(しきいち)」の設計です。すべての選考をAIに完結させるのではなく、スコアに応じて「自動合格」「人間による再確認」「不合格」の3層に分類するハイブリッド運用が推奨されます。
- High Score層(自動合格): 即座に面接調整へ。採用スピード(Time to Hire)を最大化し、優秀層を競合に渡さない。
- Middle Score層(要確認): ここにFalse Negativeが潜む。人間がAIによる要約とスコア根拠を確認し、最終判断を行う。
- Low Score層(自動不合格): 募集要件を明らかに満たさない場合のみ、不合格通知の自動化を検討。
この閾値は、採用フェーズや母集団の質に応じて動的に調整(ダイナミック・スレッショルディング)する必要があります。例えば、採用枠が埋まっていない初期段階では閾値を下げて「広めに拾う」設定にし、選考が後半に進むにつれて精度を厳格化するといった柔軟な運用がATSとの統合によって可能になります。
4. ATS統合によるリアルタイム・フィードバックループの構築
AIスクリーニングは一度導入して終わりではありません。面接の結果や最終的な採用可否、入社後のパフォーマンスデータをAIにフィードバックし、学習モデルを常に更新(ファインチューニング)し続ける必要があります。ATS(採用管理システム)とAPI連携することで、このフィードバックループを自動化できます。
「AIが高い評価をつけたが、面接での評価が低かった候補者」や、その逆のパターンを分析することで、自社の本当の「求める人物像」とAIの判断基準のズレを修正できます。この継続的なチューニングこそが、2026年以降の採用DXにおける持続的な競争優位性の源泉となります。

よくある質問
- Q. AIスクリーニングを導入すると、学歴フィルターのような偏りが助長されませんか?
- A. 適切に設計されたLLMベースのモデルは、学歴などの属性データを除外した上で、ESの記述内容(コンピテンシー)のみでスコアリングを行う「ブラインド選考」を大規模に実現できるため、無意識のバイアス排除に貢献します。
- Q. 候補者が「AI対策」として特定の単語を多用する懸念はありませんか?
- A. 最新のNLPエンジンは文脈の整合性や具体性を高く評価するため、単なるキーワードの羅列や中身のない美辞麗句は見抜かれます。また、面接評価データとの照合により、誇張表現を検知する精度も向上しています。
- Q. 導入にはどの程度の学習データが必要ですか?
- A. 自社独自のモデルをゼロから構築する場合は数千件が必要ですが、現在は汎用的なLLMに対し「Few-shot学習」や精緻なプロンプト設計を行うことで、数十件のサンプルからでも実用レベルの精度を出すことが可能です。
貴社の採用プロセスをAIで最適化しませんか?
AIスクリーニングの導入設計から、ATS連携、False Negative抑制戦略まで、専門コンサルタントが実務レベルでサポートいたします。
無料で戦略を相談するまとめ
AIによる履歴書・ESスクリーニングは、工数削減だけでなく「選考品質の平準化」と「バイアス排除」において真価を発揮します。優秀層を取りこぼすFalse Negativeを最小化するためには、最新のNLP技術を活用した文脈理解と、スコアに応じた人間による再確認プロセス(閾値設計)の精緻な組み合わせが不可欠です。ATSとAIを高度に統合し、歩留まりや面接結果をリアルタイムにフィードバックする仕組みを構築することで、自社に最適な「進化し続ける選考エンジン」を構築してください。
公開日: 2026年5月28日 / 著者: 安田 修

あわせて読みたい



参考文献
- [1] Society for Human Resource Management (SHRM) - AI in Talent Acquisition Report 2025
- [2] Natural Language Processing for Human Resources: Structuring Unstructured Candidate Data (Academic Press)